Social graph connections
On Stackoverflow the user Marin was asking this question, which sparked my interest as well.
I have always wondered how Facebook designed the friend <-> user relation.
First of all we need to consider that this is not just a friend to friend connection, but that the social connections on Facebook are used a lot and more deeply than just the first level. For example to show the user a list of “friends of friends that visited the same place in the last 30 days.” requires a little more computation thant just “Show my friends”. I did some research on this myself because I was curious how they handle their huge amount of data and search it in a quick way. I’ve seen people complaining about custom made social network scripts becoming slow when the user base grows.
The artificially generated test data contained
- 10k users
- 2.5 million friend connections
After I did some benchmarking, not even trying to bother about group permissions and likes and wall posts - it quickly turned out that this approach is flawed. So I’ve spent some time searching the web on how to do it better and came across this official Facebook article:
I really recommend you to watch the presentation of the first link above before continue reading. It’s probably the best explanation of how FB works behind the scenes you can find.
The video and article tells you a few things:
They’re using MySQL at the very bottom of their stack Above the SQL DB there is the TAO layer which contains at least two levels of caching and is using graphs to describe the connections. I could not find anything on what software / DB they actually use for their cached graphs Let’s take a look at this, friend connections are top left:
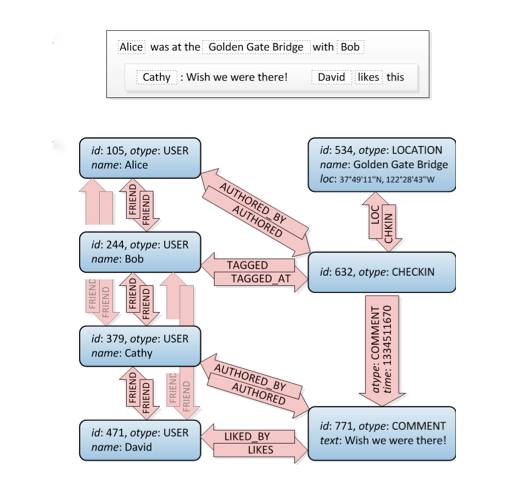
This is a graph. It doesn’t tell you how to build it in SQL, there are several ways to do it but this site has a good amount of different approaches. Attention: Consider that a relational DB is what it is: It’s thought to store normalized data, not a graph structure. So it won’t perform as good as a specialized graph database.
Also consider that you have to do more complex queries than just friends of friends, for example when you want to filter all locations around a given coordinate that you and your friends of friends like. A graph is the perfect solution here.
I can’t tell you how to build it exactly, that depends on your very service level objectives, so that it will perform well but it clearly requires benchmarking and a proof of concept.
Here is my disappointing test for just findings friends of friends:
DB Schema:
1
2
3
4
5
CREATE TABLE IF NOT EXISTS `friends` (
`id` int(11) NOT NULL,
`user_id` int(11) NOT NULL,
`friend_id` int(11) NOT NULL
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
Friends of Friends Query:
1
2
3
4
5
6
7
8
9
10
11
(
select friend_id
from friends
where user_id = 1
) union (
select distinct ff.friend_id
from
friends f
join friends ff on ff.user_id = f.friend_id
where f.user_id = 1
)
I really recommend you to create you some sample data with at least 10k user records and each of them having at least 250 friend connections and then run this query. On my machine (i7 4770k, SSD, 16gb RAM) the result was ~0.18 seconds for that query. Maybe it can be optimized, suggestions are welcome. However, if this scales linear you’re already at 1.8 seconds for just 100k users, 18 seconds for 1 million users.
This might still sound OKish for ~100k users but consider that you just fetched friends of friends and didn’t do any more complex query like “display me only posts from friends of friends + do the permission check if I’m allowed or NOT allowed to see some of them + do a sub query to check if I liked any of them”. You want to let the DB do the check on if you liked a post already or not or you’ll have to do in code. Also consider that this is not the only query you run and that your have more than active user at the same time on a more or less popular site.
I’ve started experimenting with OrientDB to do the graph-queries and mapping my edges to the underlying SQL DB. If I ever get it done I’ll write an article about it.
How can I create a well performing social network site?
Use different read and write repositories, build specific read repositories based on faster non-relational DB systems made for that purpose, don’t be afraid of de-normalizing data. Write to a normalized DB but read from specialized views.
- Use eventual consistency.
- Take a look at CQRS.
- For a social network graphs based read repositories might be also good idea.
- Use Redis as a read repository in which you store whole serialized data sets.
- Don’t over-engineer: If you don’t expect a lot users, instead check if a less complex architecture is sufficient to satisfy your requirements.
If you combine the points from the above list in a smart way you can build a very well performing system. The list is not a “todo list”, you’ll still have to understand, think and adept it to your specific requirements! https://microservices.io/ is a nice site that covers a few of the topics I mentioned before.
Projections: What I do is to store events that are generated by aggregates and use projects and handlers to write to different DBs as mentioned above. The cool thing about this is, I can re-build my data as needed at any time.
Bottom Line
I think my answer answers the question how Facebook designed their friends relationship very well but and gave you some hints on how to architect your system. Implementing a social network is easy but making sure it performs well is clearly not - IMHO.