About Validation and Anti Corruption Layers
There is a surprisingly large number of people, at least in the PHP world, who haven’t seemingly heard of or thought about when and where to put constraints on their program. Often there are DB entities that are sharing the validation with the input validation and have no clear boundary.
You can think of the roles in this way:
- Application Layer - “The bouncer”
- Domain Layer - “The enforcer”
- Infrastructure (Persistence) - “The last line of defense”
Recap: Anti Corruption Layer:
In Domain-Driven Design (DDD), an Anti-Corruption Layer (ACL) is a design pattern that acts as a boundary between different subsystems or bounded contexts, preventing the direct communication and potential corruption of their respective models.
The primary purpose of an Anti-Corruption Layer is to translate and adapt data and interactions between different contexts, ensuring that each subsystem can operate independently with its own internal language and model. This layer serves as a protective barrier, allowing changes in one subsystem to occur without causing unintended consequences or inconsistencies in the other. It typically involves a set of mapping and transformation mechanisms to facilitate communication and maintain consistency between different contexts within a complex software system.
Therefore, a “deeper” layer should not validate data that is outside its scope!
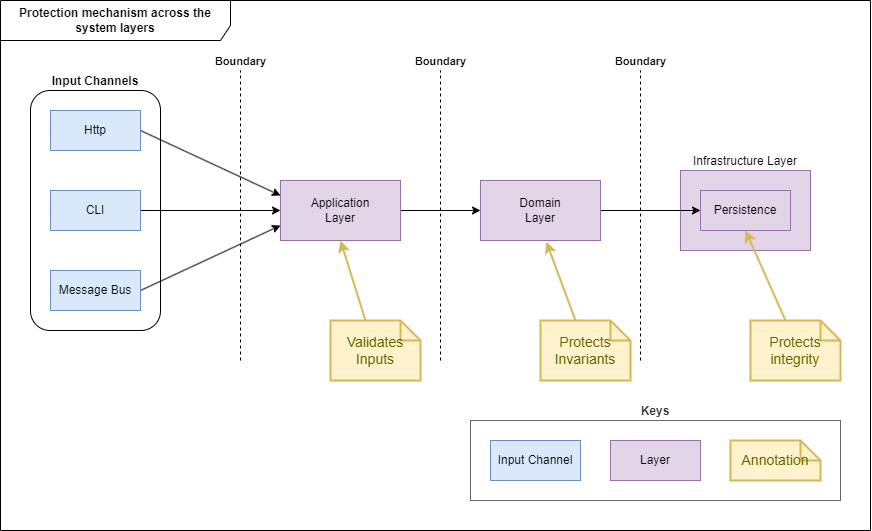
If the input was already wrong because the bouncer didn’t do its job and is passed into the domain, “the guardian” has to deal with possible violations of the trespasser. While things could already be wrong, because the guardian slept, the persistence layer is kind of a last line of defense to prevent at least inconsistencies in the data, that can be avoided by using constraints. It won’t catch a wrong calculation Validation, but it can ensure that all required data is at least present.
Let’s go over each layer and its responsibilities:
Input Validation
This is where you usually want to fail gracefully and early, to inform the client of the system about their input is not acceptable and provide reasons why.
The input can come from very diverse and different channels, in different formats, but can lead to the same outcome. Imagine an operation can be performed via CLI input, HTTP request and via an event, each of them accepts slightly different input notation, e.g. one uses camel cased, the other one snake cased and the third one is using even different field names. But why would that happen? In larger systems that grew over time, it is not uncommon that the different input channels evolved differently over time or that they have a little different requirements.
The job of the application layer here is to ensure that whatever the input is, is correct and can be turned into a proper command that is then delegated to an application service or an aggregate directly. It should also provide a proper response to the client about why the input was not accepted. Keep in mind that meaningful error messages and reasons are very important.
Also, for security reasons, you should never ever trust inputs, never. You want to validate and maybe sanitize your inputs, always!
Protection of Invariants
First, lets recap what an invariant in our context means:
An invariant refers to a rule or condition that must always be true for the aggregate to maintain consistency. An aggregate is a cluster of related entities and value objects treated as a single unit. Invariants play a crucial role in ensuring the integrity of the aggregate. For example, consider an e-commerce system where an Order is an aggregate containing OrderItems. An invariant for this aggregate might be that the total quantity of items in the order should always be greater than zero. This ensures that an order is meaningful and valid within the business context.
The domain layers job is to ensure the correctness of your business rules, they must be always true. If something goes wrong here, the process could run into an invalid state. For example, you try to process an order that has no order lines, this is something that should never happen.
How should you treat violations of the business rules? It depends on your overall design and opinion. I personally favor result object over primitive return types but I also consider domain model exceptions as a valid choice here, because the domain should never run into an invalid state and therefore the behavior is exceptional. As long as the exceptions are not becoming part of the flow, turning into exception driven development, they are totally fine. Your system design should make it impossible (commands, value objects, entities…) to pass wrong information into an aggregate that can cause an invariant to become compromised and the domain model should enforce the correctness.
Why is this different from input validation?
You can’t verify all business rules within the frontend. OK, you could check that a cart has at least one product, but this will only validate it in the frontend. Without checking that rule in your domain layer, you can’t guarantee the correctness of your business rules. And has Eric Evens wrote, the domain is the hearth of your software, it should contain your whole business logic and it should be decoupled from the application and infrastructure layer. This will make it easy to test replace everything around it and ensures that your business logic always functions as intended. It also makes the whole domain layer super easy to test.
Protection of Data Integrity
In the infrastructure layer the primary concern, at least for DB systems, should be to ensure integrity. This is can be implemented by using schemas and constraints on the schema, if the DB system supports it. But it is the DB system that will enforce this and it will very likely lead in the most cases to exceptions in your applications. I’ve seen cases in which people caught such exceptions and delegated the messages to the output the user sees, as a kind of validation. This is very problematic, because you bypass your domain to ensure the correctness of your data and rely on the infrastructure. If the infrastructure changes or has a bug, your whole “validation” is gone.
Your input validation might match some of the DB constraints, e.g. checking that an email is unique for a new account, this is however no duplication, because each layer serves a very different purpose.
Constraint examples
These constraints help maintain data consistency and integrity within a relational database by enforcing rules and relationships among tables. They prevent the insertion or modification of data in ways that would compromise the defined constraints.
⚠ They are by no means thought to replace the input validation and invariants!
Unique Constraint
Example: Ensuring Uniqueness in Email Addresses
CREATE TABLE Users (UserID INT PRIMARY KEY, Email VARCHAR(255) UNIQUE);
Primary Key Constraint
Example: Enforcing Uniqueness and Identification of Records
CREATE TABLE Products (ProductID INT PRIMARY KEY, ProductName VARCHAR(255), Price DECIMAL(10,2));
Foreign Key Constraint
Example: Maintaining Referential Integrity between Tables
1
2
3
4
5
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
ProductID INT,
FOREIGN KEY (ProductID) REFERENCES Products(ProductID)
);
Check Constraint:
Example: Verifying a Range of Values
CREATE TABLE Employees (EmployeeID INT PRIMARY KEY, Age INT CHECK (Age >= 18 AND Age <= 65));
NOT NULL Constraint:
Example: Ensuring Essential Information is Provided
CREATE TABLE Customers (CustomerID INT PRIMARY KEY, FirstName VARCHAR(50) NOT NULL, LastName VARCHAR(50) NOT NULL);
Unique Composite Constraint
Example: Ensuring Unique Combinations of Values
1
2
3
4
5
6
7
CREATE TABLE BookAuthors (
BookID INT,
AuthorID INT,
PRIMARY KEY (BookID, AuthorID),
FOREIGN KEY (BookID) REFERENCES Books(BookID),
FOREIGN KEY (AuthorID) REFERENCES Authors(AuthorID)
);
Summary
Each layer services a specific purpose and for the reason of separation of concerns, no layer should take over or leak into another layer. For example, what I have seen often is, that in a lot of frameworks, people put the validation into the persistance layers entities, or create the validators in the infrastructure layer. By defining validation rules in the infrastructure layer And reusing them for input validation, you will leak context about the infrastructure into the application layer and ignoring your domain layer, which actually should protect itself.
Changing your input We’ll now have an impact on the infrastructure layer as well. Therefore you should separate input validation and persistence from each other. Of course, it might be not very pragmatic to do that for a very small application, but as usually architecture is about trade offs. If you already know that your business logic will become more complicated, or your domain will grow, it makes perfectly sense to do it right from the beginning. And to implement the separation of concerns between those layers correctly.